
Let me start by saying that the ideals of the Open Data movement: transparency; accountability; and, citizen innovation, are ones that I hold near to my heart. Further, I admire and respect many of the leaders of the Open Data movement. However, and it may simply be my own myopia, I have yet to see many voices for caution with respect to Open Data. In particular, what concerns me most at the moment is the air of euphoria in which Open Government Data in particular is being pitched to the public. The recent series of articles around the proposed G8 Open Data Charter such as this one by Martin Tisné and this by Professor Sir Nigel Shadbolt create an expectation about data that will, at best, be very hard to fulfil and, at worst, actually shift the attention from where it ought to be. Here are some of the things I worry about.
Data as Fetish
Children’s charity organiser Benita Refson is recently quoted in the Guardian as saying: “If you’re not using data, you’re just another person with an opinion”. Somehow this quotation sums up all of my pent up apprehension about the Open Data movement. Implicit in the above is the assumption that “data”, “facts”, and “truth” are roughly equivalent. We see this in common expressions like “The data just doesn’t back it up”. This amounts to a kind of fetishisation of data as having some mystical, immutable truth quality, a quality which of course does not exist. Data is collected by people. Even when it is collected by machines, it is collected by machines designed by people. And this means that data is vulnerable to all of the vagaries that humans are prey to, bias, laziness, hidden purpose, myopia, etc. We choose what data to collect and how often and where. We choose what level of quality we would like. We choose how to represent that data and what story we think the data is backing up.

As more data accumulates our ability to see whatever we want to see increases. Researcher Kate Crawford and author Nassim Taleb have both eloquently pointed out that with larger amounts of data the ease of coming to a false conclusion only increases. Taleb says:
big data means anyone can find fake statistical relationships, since the spurious rises to the surface. This is because in large data sets, large deviations are vastly more attributable to variance (or noise) than to information (or signal). It’s a property of sampling: In real life there is no cherry-picking, but on the researcher’s computer, there is.
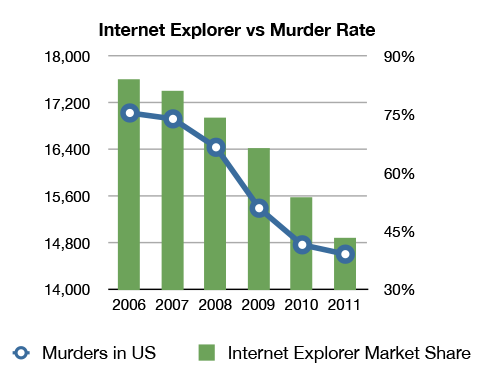
Researchers ranging from Duncan Watts to Daniel Kahneman have documented our human tendency to apply our expectations and biases to what we see. The image at the left, which recently became a popular meme on the Internet, illustrates the dangers of what can be done with too much data.
If we allow “data” to retain this mystical aura of “fact”, we run the risk of allowing ourselves to be swayed by the truthiness of the data sources we happen to like. Far more reassuring for me is the Open Science Data movement which seeks to expose these very issues by allowing other scientists to corroborate or contradict the findings of other researchers using the same data. The next Open movement I would like to see is one about Open Corroboration where we come up with better means for assessing the validity and meaning of data, news, research, etc.
Not to mention the fact that the very representation of data can influence how it is interpreted. The rise of infographics has made data even more difficult to interrogate and can be used to skew the interpretation of data. See this article on how the venerable pie chart can be used more to confuse and mislead than inform.
Data and Privacy
Also a key issue for me are the privacy implications of Open Government Data policies. If the new default for all government data is to be open, then it is inevitable that at some point the Mosaic Effect will come into play. The Mosaic Effect occurs when the information in an individual dataset, in isolation, may not pose a risk of identifying an individual (or threatening some other important interest such as security), but when combined with other available information, could pose such risk. A recent US Government policy memo instructed agencies to they must account for the “mosaic effect” of data aggregation. This can be quite hard to do and there is concern among the Open Government Data community that such a requirement could be used as an excuse to block the publication of data. A better strategy would be for the Open Government Data community to move towards a more demand-driven approach. Indeed this is the recommendation of UK researcher Kieran O’Hara in his paper, Transparent Government, Not Transparent Citizens: A Report on Privacy and Transparency for the Cabinet Office, where he suggests:
In a demand-driven regime, information entrepreneurs would ask for the datasets they felt they needed, or felt that they could use to create value, whether social value or commercial value (profit) for their own firms. This suggests two requirements.
1. Entrepreneurs must know what datasets there are.
2. There must be a screening process to ensure that privacy-threatening releases (and other problematic releases, such as ones which might threaten national security) could be challenged and blocked.
The issue of privacy is not limited to that of personal information. For instance, what right does an endangered species have to not have its location disclosed. The impact of making datasets public is hard to predict. Martin and Prof Shadbolt have done a great job in highlighting the positive but there are negative outcomes as well. Consider the saga of the map of registered gun owners that was published in the wake of the Newtown shooting. Patrick Meier has a thoughtful analysis of what happened and its implications. He ends by drawing on a basic principle from the hippocratic oath, do no harm. Addressing the “do no harm” standard in some way should be an essential pre-requisite for publishing any dataset.
Data and Complexity
Yet another concern for me is the danger of looking a complex systems in an overly simplistic way. The fact that we can measure one aspect of a complex system may give us the temptation to intervene without fully understanding the systemic role of the thing we measure. It may give us a false sense of understanding. If we have complete scrutiny of government, will that affect the way civil servants and politicians behave in an entirely positive way? Or will it simply move existing bad behaviour into areas beyond scrutiny.
A top-down, data-driven, supply-side approach to Open Government is also likely to mean a focus on what is available as opposed to what is needed. As Einstein (and others) famously said, “Not everything that counts can be counted, and not everything that can be counted counts.”
Open Data as Symptom or Cause of an Open Government
Finally, real Open Government is a cultural issue not a data issue. I worry that the disproportionate focus on datasets will distract from the harder challenge of building a culture of openness. I can’t help but wonder whether Open Government Data is a symptom of Open Government and not the other way around. Of course it is a bidirectional relationship but perhaps it only becomes bidirectional when there is a sufficient level of cultural openness in government.
This may be less of a worry in the G8 nations where there is a reasonably robust civil society to advocate for openness but for countries without that luxury, a focus on Open Government Data may not bring about the desired results.
A move towards a more demand-driven approach would have the benefit, not only of allowing due consideration of the merits and impact of releasing specific datasets but would also hopefully catalyse more of a dialogue (as I have argued for previously) between civil society and government. To paraphrase JFK, ask not what your Open Government can do for you, ask what you can do to open your government!
Pingback: Reconciling Open Data and Privacy | Many Possibilities
Pingback: The Case for Open Data in Telecoms – Many Possibilities